用一公斤DNA代替你的硬盘,靠谱吗?
最近发现关于DNA存储的文章刷屏了,源自于今年2月19号华盛顿大学和微软研究院合作在《Nature biotechnology》上发表的一篇有关DNA存储的研究成果。对此我想发表一点自己的观点,受限于我的认知,仅当是抛砖引玉了。
诚然,进入21世纪之后,这个世界的数据增长速度太快了,数据量级越来越大,按照现有发展速度传统硅基存储介质是否还能撑住,就成为了许多人关心的一个问题,大家都在探讨是否会有枯竭的那一天,如果枯竭了我们还能用什么东西来存储我们的数据。于是存储生命遗传密码的介质——DNA就成了一个非常有希望的选项。
基因是怎么与二进制联系起来的?
在谈论我们的话题之前,先来了解一下DNA是如何存储数据的。

原理本身并不复杂。
我们知道,计算机上存储的数据都是依据电压的高和低代表1和0来表示的,每一个数字、字符和标点符号都由唯一的一串01组合来构成。比如小写字母“e”的代码是:01100101,因此,任何数字化的内容(视频,音频,图片,文字)本质上都只是一串串的0和1而已。
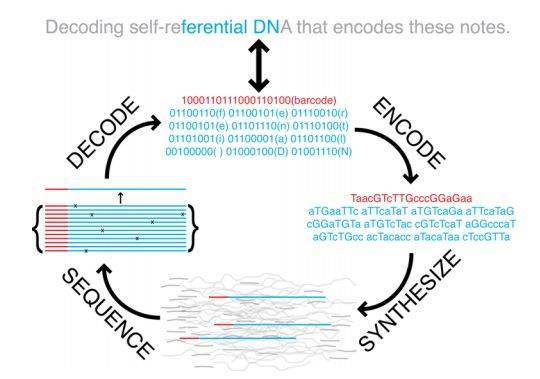
DNA存储的原理示意图,首先把英文字母转变成对应的01串,然后把这个0和1的数据串转变成由碱基A、C、G、T表示的DNA序列;编码的时候就是合成这个序列,解码的时候测序解读(图片来自Science)
那么,DNA的存储原理实际上就是把原本这些用0和1来表示的内容,换成用碱基:A,C,G,T来表示,这是一个从数字信号到化学信号的过程。而且由于碱基有四个,相比起原本的0和1,我们可以用来多表示两个状态,比如,我们可以假设用A代表00,C代表01,G代表10,T代表11。一个本来要用8bit代表的字符用DNA编码的话,只需要用4个化学碱基,比如上面的小写字符“e”编码成为DNA序列就是:CGCC。
下图是哈佛大学医学院两年前做的一个事情,他们第一次利用这样的技术把这一张“奔跑的骏马”的Gif放进了活大肠杆菌的DNA里,而且还能重新测序并解码出来。

原始影像(左)和从DNA中提取还原的gif(右),除了部分稍有模糊,准确度达90%左右。
2016年的时候,华盛顿大学和微软研究院的团队(本次NBT的成果的团队),他们更进了一步,把莎士比亚的十四行诗、马丁·路德·金的演讲原声、医学论文等资料共计739KB的数据编码成了DNA序列,并存储起来,这个技术以此为标记取得了巨大的进步。

DNA存储结构和磁盘不同,它存储的密度极高,1克的DNA就能够存下天量的信息,如果要存下当前全世界的所有数据,更是只需要1千克左右的DNA就足够了!不需要成千上万个阿里巴巴或者AWS的数据中心,看起来还更加经济实惠,貌似一切都很美好……
但是,凡事就怕这个但是。
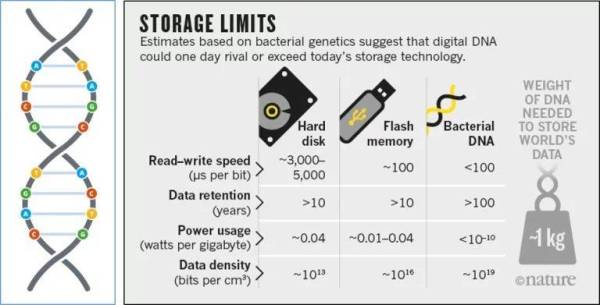
DNA存储面临的问题
目前DNA存储要发展成为真正具有实际应用价值的东西,至少还需要解决以下几个问题:
合成成本高
DNA要存储信息,首先要做的就是依据信息合成DNA序列。那么现在的合成成本是多少呢?大约0.5美元~1.0美元一个碱基!也就是说存储2bit(一个碱基)的数据需要花费大约5元~10元人民币。
按照目前的信息存储技术,一般是8bit为一个字节(Byte),2个字节(Byte)才代表一个字符——也就是说8个碱基可以编码一个字符,那么你看看,要存储200MB的数据需要花费100百万~200百万美元(1亿~2亿美元)的巨资——而200MB的大小的文件还不够一个长一点的短视频大啊!更何况现在动不动就几个GB的电影呢。
因此,碱基合成的成本是第一个需要解决的难题。如果成本无法降低一百万倍,那么无法进入实用环节,而如果不能降低几亿倍甚至几十亿倍,那么我认为这个技术将很难被大规模使用。
合成速度慢
这个问题可能更要命。我们现在磁盘的存储速度是多快呢?磁盘的读写毕竟是电磁信号,信息状态的改变是以光的速度在发生的——当然磁盘在读写数据的时候需要进行非常多的定位、查询、比较、校验等一系列复杂的操作,因此远低于光速。然而即便如此,目前普通的SSD硬盘读写速度也有300MB/s~500MB/s,差一些的高速硬盘也在100MB/s左右!
而DNA的合成速度有多快呢?DNA的合成依赖于一系列的化学反应,大肠杆菌的DNA(合成)复制速度大约是1000碱基/秒,看起来很快了,但它的速度在电磁面前根本不值一提,我们可以算一下合成200MB的数据需要多久呢?200×1024×1024×8 /1000/86400=19 天!也就是说现在磁盘1秒钟写入的数据,我们大约需要花差不多三周的时间才能完成!
这是什么概念?据统计截至2017年全球数据大约有16 ZB(泽字节,每泽字节为10万亿亿字节,仅指数字化的数据),那么假设我们要把这个量级的数据存到DNA中,大概要花多长时间?我斗胆计算了一下,发现竟然需要40亿年!40亿年啊,同志们,地球才多老啊?这还是在不考虑数据校验的状态下。
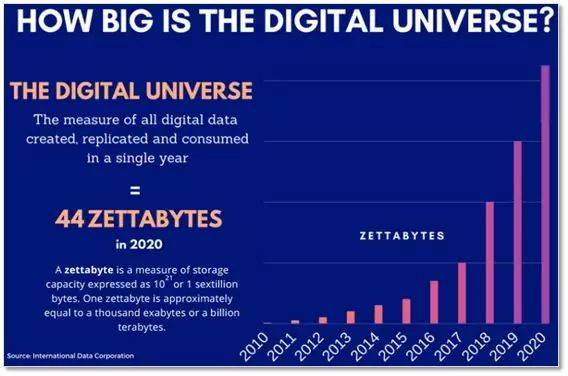
更有甚者,据说到了2020年,全球数据更是要达到惊人的44ZB的量级!当然,上面的结果是在单个反应下的合成速度,事实上,我们可以让全世界成千上万的实验室或者机构一起来做,同时随着技术的发展可以设计出DNA大规模并行合成技术,就如同大规模并行测序一般,通过工程上的规模化弥补先天的缺陷,将速度提高几百万到几亿倍。
但这对合成的技术就提出了更高的要求,因为这个过程不可避免的会导致我们放弃数据原有的连续性,那么该如何把这些打散的数据在读取的时候重新正确地组合到一起也将成一个重要的问题。除此之外,还有实时合成记录的问题呢。
数据读取无法实时
DNA存储的数据要读取出来目前是通过测序这条路。虽然相比于DNA合成,测序的问题小了很多。按照当前最新的测序技术——一台NovaSeq测序仪基本上能够在两天的时间内完成3Tb~6Tb数据的解码。成本相比于DNA合成也基本低了一百万倍左右。即便如此,真要实用,依然有许多问题必须解决。
比如我们在看电影的时候,你不会真的希望对着一台测序仪看吧,另外刷微信、微博、头条、知乎等的操作是多么频繁和快速,DNA解码要如何做到实时并且保障信息的可逆回滚,挑战不小啊(中间通过磁盘来缓存吗?)。
数据随机读取仍需进一步解决
所谓随机读取数据的意思就是:我想打开哪一份文件就打开哪一份,并且我想读取其中的哪一段就读取哪一段,而且这个操作必须要在很短的时间内实现。这对于存储在DNA中的数据文件来说要如何才能够做到?

2月19日,华盛顿大学和微软研究院合作发表在《Nature biotechnology》上的这篇文章“Random access in large-scale DNA data storage”,就是为了解决这一个问题。它最大的突破是设计了一种办法来解决这个随机读取的问题——文章的标题也能够看出来。他们把35份相互独立的数据文件(大小约200MB)合成为DNA序列存储起来,并且精心设计特定的引物(primer,即引子,是一小段单链DNA或RNA,作为DNA复制的起始点),标记每一个文件在DNA序列上的地址(如同硬盘的存储路径一样)。这个时候,当我们要重新读取这些数据的时候能够按照需要快速跳到特定某份文件的位置上进行测读。
比如我们想要获取第10份文件上的内容,如果放在从前,我们只能全部测序了才能得到,但是借助这个技术,我们可以直接跳到这份文件所在的位置上,把它测读出来。
虽然这个技术已经做到了这一步,应该说取得了不小的进步,但也应该清晰地认识到它距离真正应用还有不小的距离。另外,依我愚见,这个方案也还有不完美的地方:
DNA存储技术会颠覆现有的计算机存储技术吗?
我认为不会,即便DNA存储技术成熟了,两者也将一直共存,直到被其他的介质代替了。DNA存和读的效率远不及磁盘的速度,这是自然原理所决定的,一时半会无法解决,但它对数据保存的耐久性却很好。
因此,DNA存储更可能的是替代磁带存储,把不需要经常使用的“冷”数据归档保存,把重要的数据进行冷存备份,而且鉴于DNA本身体积小、几乎不耗电的特点、保存也方便,确实可以节省很多的社会资源。
小结
当然,我不是DNA合成领域的专家,写这一篇文章不是为了抨击DNA存储的成果,相反,我非常认同DNA存储技术的发展,更希望看到它在未来的应用。
但我也很谨慎,会想这是否真的是最好的方法。我们说DNA对数据存储的密度远高于现在的磁盘,但如果我们能够操纵原子的量子状态,利用原子的量子状态(比如:自旋)存储数据那样密度岂不是更高?而且还不会有速度限制上的问题。
有些媒体的盲目夸大,甚至罔顾事实,一旦发现一个新东西就总觉得它是万能的,总认为它将如何“颠覆”一切等诸如此类的言论。过分的夸大甚至曲解对于科学技术的发展不是好事,也不能引导公众对其做出客观的判断。技术的发展有其自身的规律性,该到它颠覆一切的时候,不用说也会自然发生,现在就耐心看它长大。
文章来源:中国生物技术信息网

{replyUser1} 回复 {replyUser2}:{content}