腾讯医疗AI实验室:3篇论文被国际顶尖会议收录
近日,腾讯在医疗 AI 领域的学术研究获得实质性进展,旗下医疗 AI 实验室共有 3 篇论文分别被 KDD 2018、SIGIR2018 、COLING 2018 三个国际顶尖学术会议收录,论文的主要研究方向为医疗知识图谱中实体关系的发现和应用。
在医疗领域,专业知识和病人信息均存储在复杂多样的文本中,如医疗文献、临床病例等。文本数据中的多重表达形式和噪声给基于文本数据的AI医疗服务带来挑战和困难。知识图谱能够以结构化的形式存储医学中实体以及实体间的关系,能将信息表达成更容易被计算机处理的形式。腾讯医疗 AI 实验室利用知识图谱及其相关技术,如自然语言处理、知识抽取、信息检索、知识表示与推理等,从医疗文献、医学指南和临床病历中挖掘隐含的医学知识,将大数据转化为知识图谱,使得知识查询和更重要的形式化推理变得可行,有医学依据,辅助临床决策,赋能基于人工智能的医疗产品。
此次腾讯医疗 AI 实验室研究成果入选的三大学术会议分别是:SIGKDD,数据挖掘研究领域的顶级国际会议;SIGIR,信息检索领域的顶级国际会议;COLING,自然语言处理领域的重要国际会议。
腾讯医疗 AI 实验室负责人范伟介绍,“医疗知识图谱是推动人工智能应用于医疗领域的核心驱动力之一,如何更好地利用自然语言处理、知识抽取等相关技术,从形式多样、信息杂乱的各种医疗数据中,抽取结构化的医疗知识,结构化存储实体的详细属性以及实体之间的关系,我们在不断优化提出问题并尝试给出新的解决思路和研究方法。”
以下为收录的三篇论文概要:
入选 KDD 2018:基于生成模型的医疗实体关系抽取(Onthe Generative Discovery of Structured Medical Knowledge)
研究成果:创造性地从生成模型的角度研究医疗实体关系,减少了对语料数据和专家标注的需求
在医疗知识图谱中,实体三元组以结构化的形式描述了医学领域中实体间的各种关系。为了获得医疗领域实体三元组,现有方法大多需要搜集大量语料,或过多依赖于专家的标注。如图 1 所示,本文提出的算法 CRVAE (Conditional Relationship VariationalAutoencoder)利用已标注的实体三元组在自然语言表述上的共性和差异,对多种医疗实体关系类内的数据分布进行联合编码,进而从生成模型的角度去发现未被标注的关系实体三元组。该方法减轻了传统判别模型对于外部资源的过度依赖,并且不依赖于医疗实体关系类间的差异进行建模。
实验表明,算法 CRVAE 不仅能够在外部资源有限的条件下,以 92.91% 的支持度生成属于某个特定医疗关系的实体三元组,其生成的结果拥有 77.17% 的准确率且生成结果中有 61.93% 的样本未曾出现在训练数据中。
在未来,我们将尝试利用生成模型进行不同粒度、不同医疗子领域的无监督知识发现。同时,我们也期待将生成模型作为一种有效的数据增强方式,赋予医疗领域更多人工智能的应用。
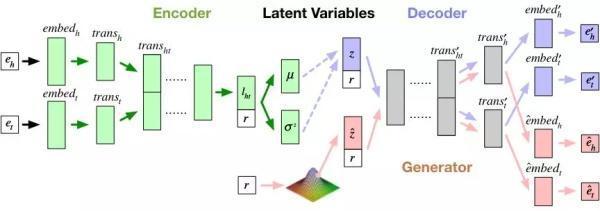
▲ 图1. CRVAE模型架构图示
2. 入选 SIGIR 2018:具有知识感知能力的答案排序模型(Knowledge-aware AttentiveNeural Networkfor Ranking Question Answer Pairs)
研究成果:证明了利用知识图谱可显著提高问答系统的性能
在基于人工智能的医疗产品中,对话系统作为最终呈现形式有着广泛的应用。答案排序是对话系统中的重要部分,最近受到越来越多的关注。然而,已有相关工作在除关注上下文之外,对起着重要作用的背景知识却关注很少。对此,本文提出了KABLSTM(Knowledge-aware AttentiveBidirectional Long Short-Term Memory),这是一种具有知识感知能力的双向长短记忆模型,它利用知识图谱引入的背景知识来丰富问答的表征学习。
如图 2 所示,本文开发了一个知识交互式学习架构,其核心是一个上下文引导的注意力神经网络,可将知识图谱中的背景知识嵌入整合到句子表示中;最后结合知识型注意力机制模块,对问题和答案中的各个部分进行有效的相互关联。在 WikiQA 和 TREC QA 数据集上的实验结果证明了该方法具有一定有效性。在此工作中,利用知识图谱来辅助问题和答案的表示学习。在后续的工作中,我们将研究利用知识图谱进行直接推理,来帮助医疗问答系统。
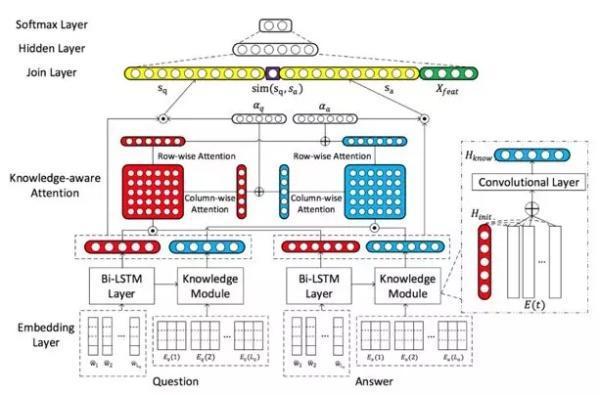
▲ 图2. KABLSTM模型架构图示
3. 入选 COLING 2018:基于远程监督具有协同消噪能力的实体关系抽取模型(CooperativeDenoising for Distantly Supervised Relation Extraction)
研究成果:创造性地提出能够减少数据噪声对实体关系抽取性能影响的方法
在知识图谱的构建过程中,远程监督(Distant Supervision)能够减少对标注数据的需求,因此适合从非结构化文本中进行关系抽取。然而,该方法有可能受到训练数据噪音过大的影响,性能受到限制。为解决这个问题,本文提出了一种协同消噪的模型 CORD (COopeRative Denoising framework),该方法由两个神经网络和一个协同模块组成,如图 3 所示,两个神经网络分别在文本语料库和知识图谱领域进行学习,再通过一个自适应的双向蒸馏模块(adaptive bi-directional knowledge distillation)完成它们间的相互学习,达到消除噪声的目的。实验表明,该方法在噪声较大的数据上有较明显的效果提升。
在医疗领域,医疗文本、医疗影像等不同模态、不同来源的数据包含着互补的丰富信息。在后续研究工作中,我们将利用多模态、多源数据进行更加可靠的去噪和医疗知识提取。
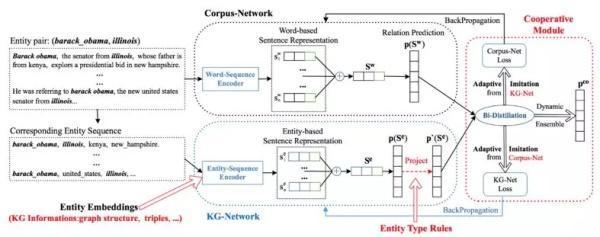
▲ 图3. CORD模型架构图示
医疗知识图谱作为人工智能应用于医疗领域的前沿课题,对推动“AI+医疗”的发展有着重要意义,将为医疗行业的发展带来新的契机。当前,腾讯在“AI+医疗”领域的学术研究在稳步前进并获得国际学术界的认可,有利于更好的推动“AI+医疗”产学研结合,加速医疗 AI 应用落地,为医疗赋予 AI 动能。
腾讯医疗 AI 实验室是腾讯医疗专为医疗领域打造的人工智能实验室,采用美国-中国双中心模式,目前在硅谷、北京、深圳设立了三个分支。主要研究方向包括:通过研发临床辅助决策支持系统向各级医务工作者提供服务,以提高医生用户在医学科研、患者诊疗、疾病防控等方面的工作效率;通过研发基于无可穿戴传感器纯视频分析技术的运动障碍性疾病评测系统,可用于帕金森病的日常评测、脑瘫患者术前步态评测等方面,实现自助评测,以提高医生工作效率,减低患者评测成本;通过研发医学知识引擎,构建权威全面的医学知识库,并提供对外知识库查询等平台化服务,降低医疗人工智能辅助决策类产品的技术门槛,通过知识共享的方式与合作伙伴共同打造医疗AI的技术和服务生态圈。实验室的目标是通过世界领先的 AI 技术,构建良好的技术生态,服务于医患双方,提高工作效率、优化就医体验,缓解医疗资源分布不均等问题,同时着重落实分级诊疗国策。

来源:机器之心
版权及免责声明:本网站所有文章除标明原创外,均来自网络。登载本文的目的为传播行业信息,内容仅供参考,如有侵权请联系答魔删除。文章版权归原作者及原出处所有。本网拥有对此声明的最终解释权。
{replyUser1} 回复 {replyUser2}:{content}