《Nature》重磅:谷歌AI自动重构3D大脑 最高精度绘制神经元
 AI能够映射大脑神经元。人类大脑包含大约860亿个神经元,并且一个立方毫米的神经元可以产生超过1000TB的数据。由于其庞大的规模,绘制神经系统内部结构的过程是计算密集和繁琐的。为了加速这一过程,谷歌和德国马克斯普朗克神经生物学研究所的研究人员开发了一种基于深度学习的系统,可以自动映射大脑的神经元。这是 AI 解决21世纪重大工程挑战的又一成功例证。
AI能够映射大脑神经元。人类大脑包含大约860亿个神经元,并且一个立方毫米的神经元可以产生超过1000TB的数据。由于其庞大的规模,绘制神经系统内部结构的过程是计算密集和繁琐的。为了加速这一过程,谷歌和德国马克斯普朗克神经生物学研究所的研究人员开发了一种基于深度学习的系统,可以自动映射大脑的神经元。这是 AI 解决21世纪重大工程挑战的又一成功例证。
谷歌AI负责人Jeff Dean演讲时总爱用一张PPT,那就是用机器学习解决21世纪重大工程问题,其中就包括人脑逆向工程,谷歌和马克思普朗克研究所等机构合作,从理解大脑神经网络的图像入手,试图重构生物神经网络。
在之前的报告中,Jeff Dean提到他们提出了一种模拟生成神经网络的算法“Flood-Filling Networks”,可以使用原始数据,利用此前的预测,自动跟踪神经传导。
今天,描述相关研究的论文正式在 Nature Methods 发表,他们的方法不但能自动分析大脑连接组数据,还将准确度提高了一个数量级,突破了当前连接组学的一个重要瓶颈!

研究人员表示,他们的算法比以前的自动化方法准确度提高了10倍。这是 AI 在推动基础科学发展的又一项成功例证,大大推动了我们对人脑数据的解析,也有助于构建更好的人工智能。
正如 Jeff Dean 所说,机器学习能够用于帮助乃至解决人类重大工程挑战。
自动分析大脑连接数据,将精度提高一个数量级!
连接组学(Connectomics)旨在全面地映射神经系统中发现的神经元网络的结构,以便更好地理解大脑如何工作。这个过程需要以纳米分辨率(通常使用电子显微镜)对3D脑组织进行成像,然后分析所得到的图像数据,追踪大脑的神经节并识别各个突触连接。由于成像的高分辨率,即使只有一立方毫米的脑组织,也可以产生超过1000TB的数据!再加上这些图像中的结构可能非常微妙和复杂,构建大脑连接图的主要瓶颈实际上并不在于获取数据,而是如何自动分析这些数据。
今天,谷歌与马克斯普朗克神经生物学研究所的同事合作,在Nature Methods发表了《使用Flood-Filling网络高效自动重建神经元》(High-Precision Automated Reconstruction of Neurons with Flood-Filling Networks),展示了一种新型的递归神经网络如何提高自动解析连接组数据的准确性。不仅如此,与先前的深度学习技术相比,提高了一个数量级。

使用 Flood-Filling 网络进行三维图像分割
在大规模电子显微镜数据中追踪神经节是一个图像分割问题。传统算法将这个过程分为至少两个步骤:首先,使用边缘检测器或机器学习分类器找出神经节之间的边界,然后使用watershed 或 graph cut 等算法,将未被边界分隔的图像像素分组组合在一起。
2015年,谷歌与马克斯普朗克神经生物学研究所的团队开始尝试基于递归神经网络的替代方法,将上述两个步骤统一起来。新的算法从特定的像素位置开始生长,然后使用一个循环卷积神经网络不断“填充”一个区域,网络会预测哪些像素是与初始的那个像素属于同一个物体。
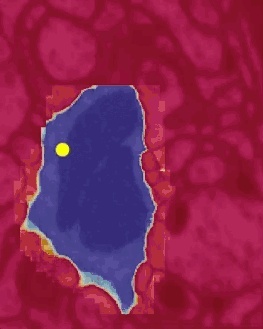
在2D中分割物体的Flood-Filing网络。黄点是当前焦点区域的中心;随着算法不断迭代,检查整个图像,分割区域不断扩展(蓝色)。
通过预期运行长度来测量准确性,优于以往深度学习方法
自2015年以来,谷歌与马普研究所的研究人员一直致力于将这种新方法应用于大规模的连接组数据集,并严格量化其准确性。
他们提出了名为“预期运行长度”(ERL)的概念:在大脑的3D图像中给定一个随机的神经元,在跟踪出错前,能够对其追踪多长距离?
这是一个典型的“失败前的平均时间”的问题,不过在这个问题中,研究人员查看的是两次失败之间的空间,而不是时间。ERL吸引人的地方在于,它可以将线性的物理路径与算法出现个别错误的频率联系起来,以便于直接计算。对于生物学家来说,ERL的数值与生物学上的数量存在相关性,比如神经系统中不同部分的神经元的平均路径长度。
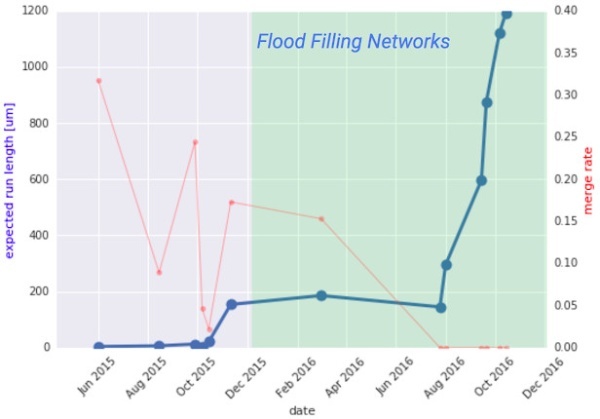
采用ERL方法(蓝色线)的结果表现最好,红色线表示“合并率”,即两个独立的神经元被错误地当成一个目标进行跟踪的频率。将合并率保持在一个很低的水平,对于研究人员手动辨别并改正其他错误具有很重要的意义。
研究人员利用ERL方法测量了100万立方微米的斑胸草雀大脑扫描图像中的神经元真实数据集,结果表明,新方法比以往使用同样数据集的其他深度学习途径的表现要好。

ERL算法追踪斑胸草雀大脑中的一个神经元
重构斑胸草雀大脑中的一部分。不同颜色表示不同区域,都是使用Flood-Filing网络自动生成的。金球代表使用以前的方法自动识别的突触位置

斑胸草雀又称珍珠鸟,属于雀形目梅花雀科,分布于澳洲。 身长10-11cm,主要以禾本科植物的种子为食。 斑胸草雀与其他梅花雀科鸟类同样有高度的社会性,雄鸟会通过"唱情歌"向雌鸟求偶。常用于脊椎动物脑、行为和演化研究的模型。
研究人员利用新的Flood-Filling网络,对斑胸草雀大脑中的一小部分神经元做了划分。将来,他们计划利用突触级分辨率技术继续改进连接重构。
为了帮助更大的社区推进与该技术的相关研究,Tensorflow代码现已开源,谷歌还公布了他们开发的面向3D数据集的WebGL可视化软件,用于理解和改进该研究结果。
Flood-Filling网络的训练、推断和结构
在今天发表于 Nature Methods 的论文中,研究人员详细介绍了他们的方法。当然,我们最关心的还是 Flood-Filling 网络的训练,推断和结构。
研究人员在论文中写道,我们得到了一个96x96x114μm的区域,并用串行块面EM25成像,其分辨率为9×9×20nm。 对于分类器训练,数据集的一小部分由KNOSSOS的人类注释器分段。然后使用这些注释作为训练FFN的ground-truth。
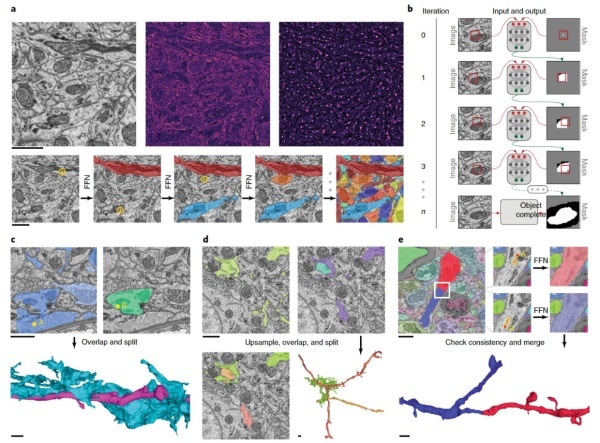
图1:分割pipeline,包括共识(consensus)和集聚程序
FFN具有两个输入通道:一个用于3D图像数据,一个用于对象形状(叫做预测对象图(POM)的数据结构)的当前预测。对于每个体素(voxel),POM编码(使用0和1之间的值)算法对体素是否属于当前正被分割对象的估计。
在训练期间,通过在每个49×49×25体素训练样本的中心播种(seed)单个体素来初始化POM。 我们在远离假定单元边界的位置自动生成单体素种子,以避免合并(两个或多个进程错误地彼此连接)。 在网络推断的每次迭代之后,POM的值用于通过随机梯度下降来调整网络权重,每使用一个体素,交叉熵(cross-entropy)损失26(图1a,b和方法)。
每个推理步骤的结果影响FOV移动的位置、决定哪个体素分类被冻结以及神经突扩展何时完成。
FFN的核心体系结构是多层卷积神经网络(CNN),它基于输入数据和先前的POM值在每次迭代期间更新POM值。此实验在FFN实施中选择使用单个3D FOV尺寸(33×33×17体素,297×297×340 nm)进行EM数据输入,推理输出和循环反馈。
预期运行长度的工作原理
不规则检测和自动组织分类
许多推理错误发生在数据不规则处,例如切割伪像(cutting artifacts)或对齐(alignment)错误。在songbird volume EM数据集中,由于不规则性过于频繁而不能被忽略,但数量太少而无法有效学习(最多影响音量的1%)。 我们没有在训练集中丰富它们,而是通过互相关(cross-correlation方法)检测它们,并防止超级体素跨越任何不规则性。
当神经纤维被诸如somata或血管的组织结构中断时,分割质量通常会降低,这些组织结构比典型的轴突,树突和FOV大几个数量级。 为了防止FFN冒然进入这种结构,我们训练了一个单独的CNN,称之为组织分类CNN,并用它来描绘这种结构。
滞后和近似尺度不变性
由FFN重建的神经突形状取决于初始种子在神经突内的位置,并且当重建神经突的顺序或种子的位置改变时,它会发生显著改变。事实上,这种可变性可用于检测和消除在校对过程中难以修复的合并,代价是产生一些额外的分裂(两个过程彼此错误地断开),这些是比较容易修复的。我们还研究了不同分辨率下数据集的重新取样,并发现在五个分割中的对一个oversegmentation consensus 合并的数量最大程度的减少了(82倍)(分割率仅增加了两倍)(图1c,d和方法)。
分割pipeline
我们将数据对齐、组织分类、FFN推断、过分割共识、FFN-scored集和生物合理性测试结合到pineline中,并用它来分割整个斑胸草雀的体积。
大规模分割精度
为了测量分割结果的准确性,我们对单个神经元进行了骨骼化处理。人类注释者使用KNOSSOS软件手工地将单个神经元的结构注释为一组节点和边缘。我们创建了一个调优集和一个测试集,分别包含12和50个神经元,中位数为0.8 mm和1.9mm,总路径长度为13.5mm和97mm(27%和34%轴突)。我们专门使用这些集合来优化分割pipeline的超参数,并分别对性能进行评估。
在观察到的与自动分段重叠的基础上,我们将ground truth骨架的每条边分别归类分段中的重构、省略(一个或两个端节点不在任何段中)、分裂或合并分段的一部分。在成像体积中,大约1.4%的路径长度被人工骨骼化。这使我们能够自动地检测出发生的所有分裂,但观察到的合并数量相比真是数量严重减低。
最后,我们计算了一个预期的运行长度(expected run length,ERL),它测量了属于随机放置的起始点的片段中包含的平均神经元轴突长度。
我们的最终重构(FFN-c,应用了整个pineline)的ERL达到1.1毫米,并在97毫米神经元轴突长度的骨架测试集中包含四个合并(见:图2为定性分析,图3为定量分析,包括分裂计数)。

图2:基于检测的分割精度分析

图3:分割精度的定量分析
为了更好地评估FFN-c的性能,我们对斑胸草雀数据集应用了两种最先进的替代方法,并量化了分割性能。第一个(“baseline”)方法结合了一个3D卷积神经网络,利用网格搜索对关联图域参数进行了优化,并对标记数据进行了随机森林分类器的聚类。第二种方法是SegEM,其中3D 卷积神经网络边界预测 boundary prediction被用分水岭算法进行过分割。
通过这些途径,baseline方法实现最高的ERL(112μm;图3),比FFN的结果差一个数量级。
神经突类型的误差
我们手工将ground truth骨架中的神经突碎片分类为轴突或树突,并且记录了182个树突棘的基部和头部的位置。然后,我们使用这些数据来测量不同神经突类别的FFN-c分段的错误率。我们观察到自动重建在识别树突棘方面优于人类注释(分别为95%和91%recall率)。虽然两组的精确度都接近100%,但自动化结果略高(自动重建为99.7%和100%,而人工重建的树突和轴突分别为98%和99%),自动重建组中的树突和轴突recall率不如人类注释所获得的(自动化过程分别为68%和48%,而人工生成的数据分别为89%和85%)。
其他物种和成像方法
FIB-25是果蝇视神经叶的公共数据集,通过8×8×8 nm的聚焦离子束扫描EM成像,已被用于基准分割方法。 同样用作公共分割基准,SNEMI3d是小鼠体感皮层的数据集。FFNs应用于held-out测试集,获得了“超过人类”的表现。
论文原文:High-precision automated reconstruction of neurons with flood-filling networks

来源:新智元
版权及免责声明:本网站所有文章除标明原创外,均来自网络。登载本文的目的为传播行业信息,内容仅供参考,如有侵权请联系答魔删除。文章版权归原作者及原出处所有。本网拥有对此声明的最终解释权。
{replyUser1} 回复 {replyUser2}:{content}